
INTRODUCTION
Why do companies invest in AI and see no results?
Most organisations that leverage AI with varying degrees of success don't build or train their own models from scratch. In business practice, companies typically use ready-made, publicly available models—whether large language models or specialised AI tools. These models come pre-trained and off-the-shelf, which might suggest that data becomes a secondary concern. This is a fundamental misconception.
Even the best AI model is useless without access to the right data. A language model may be brilliant at understanding language, but if it's meant to create or translate content aligned with a brand's tone of voice, using the correct terminology and preserving all the nuances that matter to the business, it needs access to information about the brand, products, and target audiences, detailed content guidelines, glossaries, and more. A risk analysis model may be highly sophisticated, but without complete and consistent financial data, it will generate worthless results. The quality of what AI delivers in any given process is directly dependent on the quality of the data feeding into that process.
In an IBM study (IBM GLOBAL AI ADOPTION INDEX – ENTERPRISE REPORT, 2023), the second most common barrier to AI adoption cited by respondents was excessive data complexity (24% of all responses)—right after the lack of AI-related skills, experience, and knowledge (32%).
At the same time, many organisations make the same mistake—they invest in models and technology first, only to discover later that their data isn't ready. This is the inverse of the approach taken by companies that achieve real business value from AI. The success of an AI implementation doesn't depend on technology; rather, it hinges on organisational maturity, and above all, on how the organisation approaches its data.
Planning to implement an AI project in your organisation?
To help you make the right decisions and properly prepare for this project, we're sharing our proprietary AI Transformation Canvas by Shiftum.
In the canvas, you'll find:
- a ready-to-use framework covering all the key areas of AI project planning
- a blank version, ready to print and work with
- a version with guiding questions for each section, designed to help you understand what information matters at every stage of planning
Data as a Strategic Asset
AI transformation has forced many organisations to rethink how they view data. Many companies treat data as a by-product of operations—something that simply emerges in the course of doing business. ERP systems generate transaction data, CRMs collect customer information, and so on, but these resources are often not treated as assets requiring deliberate and consistent management.
This perspective must change in the context of AI implementations: organisations that treat data as a strategic asset and invest in managing it deploy AI faster and achieve better results. This isn't a technical matter—it's a strategic one, requiring decisions at board level.
In AI projects, to simplify somewhat, we can talk about two types of data:
- Data for training models – this is the domain of companies building their own AI models. It requires vast historical datasets for the model to "learn" from. Most organisations implementing AI don't need to deal with this—they use models already trained by specialised technology companies.
- Data needed to run AI processes – this is the domain of every organisation implementing AI. Even an off-the-shelf model needs data to perform a specific task. An AI assistant needs access to the company's knowledge base. A recommendation system needs data on customer preferences. A reporting automation tool needs up-to-date financial data. Without this data—or with poor-quality data—the AI process won't generate value.
Referring to the AI Transformation Canvas we've prepared for our clients, the key questions for strategic planning are:
- What data assets already exist that are critical for this use case?
- Who owns the data?
- How complete, current, and consistent is the data?
- What data gaps could limit success?
- What risks exist around data quality or access?
In the remainder of this article, we'll explain what these questions really mean and what's worth considering at the planning stage.
Trust in AI Starts with Trust in Data
AI is built on statistics. A model's job is to predict, in the context of a query, the most semantically relevant token. At the same time, an AI model makes its predictions based, among other things, on the data it receives in the process. In most cases, AI won't be able to detect that the quality of the data you're providing has dropped, that it's outdated, or that errors and gaps have crept in. Trust in data is therefore the foundation for trust in AI. This is a fundamental relationship that organisations often overlook.
The credibility of results delivered by a model has two sources:
- The quality of the model itself – does it "understand" the task, does it process information correctly? When using proven, off-the-shelf models from reputable providers, appropriately matched to the task, this source of risk is relatively well controlled.
- The quality of input data – has the model received the right, complete, filtered (task-appropriate), and up-to-date information to process in a given workflow? This source of risk lies with the organisation implementing AI.
For example: a company implements AI Translation Engine—a translation tool powered by AI. The language model used by the translation engine is excellent at understanding languages and delivers pretty good translations right out of the box. However, like any translator, it needs detailed guidelines to know how to translate technical terms, what not to translate, or, for instance, what tone of voice the company uses when communicating with customers on Instagram. It learns all this from the guidelines it receives and stores in its memory. If those guidelines contain errors, or aren't regularly reviewed and updated, translation quality may decline over time.
Four Dimensions of Data Readiness for AI Processes
In the AI Transformation Canvas, you'll find space to answer a crucial question—is your data ready for AI? More specifically, do you have data that will be sufficient for the particular process you're planning, and can you actually use it?
But what does "data ready for AI" actually mean? We can talk about four key dimensions that determine the quality of data needed to execute a process: completeness, currency, consistency, and accessibility.
Completeness – Do we have all the data we need?
Data completeness isn't just about "whether data exists," but "whether we have all the data needed to perform the task." An AI process is only as good as the data feeding it.
Example: we're implementing an AI system for sales lead qualification. The system needs information about lead source, industry, company size, and interaction history. If the CRM consistently lacks industry information (because sales reps don't fill in that field), the model won't be able to factor this criterion into qualification—even if industry is an important consideration in sales potential analysis.
Currency – Does the data reflect reality?
In AI processes, outdated data is just as problematic as incomplete data. The model operates on what it receives—it doesn't know the information is a year old.
Example: an AI Support Assistant supporting the customer service department draws information from systems such as ERP, CRM, OMS, and the product database. If, for instance, a product price changed two days ago but the product database hasn't been updated, the assistant will use outdated information. The problem doesn't stem from model limitations—it stems from how the data update process works.
Consistency – Do data from different sources tell the same story?
Most AI processes require combining data from multiple systems. If the same information is recorded differently in different places, the AI process receives conflicting signals or may not be able to use such data at all.
Example: an AI system for customer value analysis pulls data from CRM (contact details, interaction history), ERP (order history, payments), and the support system (ticket history). In the CRM, the customer is recorded as "ABC Ltd.," in the ERP as "ABC Limited," and in the support system as "ABC Company". Is this one customer or three? Without a consistent identifier, the AI model may treat one customer as three different ones.
Accessibility – Can data be delivered to the AI process?
Data may be complete, current, and consistent, but inaccessible to the AI process. The reasons are most often technical (e.g., no API, incompatible formats), organisational (data in silos, no authorisation to share), or legal (GDPR restrictions, confidentiality agreements).
Example: A company wants to implement an AI assistant to help customer service staff quickly find information about products, complaints procedures, current offers, and typical problem-solving scenarios. All this information theoretically exists within the organisation—scattered across dozens of Word documents, Excel spreadsheets, presentations, and internal wikis. The problem is that these materials aren't available to the AI process in a usable form. Each document has a different structure and contains formatting elements, graphics, and tables with inconsistent layouts. Extracting knowledge from them would require costly and time-consuming processing of each file individually. For the AI assistant to effectively answer employee questions, the company must first transform this scattered knowledge into a structured database—for example, a collection of Markdown files with a clear topic hierarchy and consistent formatting conventions. Only then will the data become truly accessible to the AI process.
The Data Silos Problem – A Barrier to AI Processes
When implementing AI in a large organisation, you often encounter yet another barrier. AI models are frequently capable of performing complex tasks, but they need access to diverse data. The more advanced the use case, the more data sources must feed the process. And data in organisations is often scattered across silos.
A typical scenario might look like this: a company wants to implement AI to predict which customers are likely to cancel their subscription. To do this, the AI process needs information from multiple sources:
- Purchase history (sales system)
- Customer service contact history (ticketing system)
- Payment history and any delays (finance system)
- Activity in digital channels (marketing automation system)
- Complaints history (quality management system)
Each of these systems is managed by a different department. Each has different formats, different standards, different update cycles. Combining this data into a coherent customer picture that can be delivered to the AI process is an organisational challenge, not a technical one. No AI model, no matter how good, will solve the silos problem.
The question from the AI Transformation Canvas: "What data gaps could limit success?" often reveals silos alongside gaps in essential data. The data theoretically exists within the organisation, but is inaccessible to the AI project because it "belongs" to another department.
Personal Data and GDPR – The Hidden Risk in AI Implementations
There's another issue that's often overlooked in the early phases of AI projects, yet can have serious legal and business consequences: personal data protection in the context of using AI tools.
Many AI tools, particularly those based on large language models, operate on a cloud model. Data we send to such tools—whether as queries or documents for analysis—may be processed on the provider's servers. What's more, some providers reserve the right to use data submitted by users to further train and improve their models.
If an employee pastes into an AI tool the content of a customer email containing personal data, a contract excerpt with contractor details, or a client list with phone numbers—this information may end up in an external provider's systems. In the worst-case scenario, it could be used to train the model, meaning fragments of this data could "leak" into responses generated for other users.
GDPR places an obligation on data controllers to maintain control over where and how personal data is processed. Transferring data to an external AI tool without appropriate safeguards may constitute a regulatory breach—with all the consequences that entails (financial penalties, reputational damage, claims from data subjects).
Before implementing an AI process that uses customer or employee data, an organisation should establish clear rules for data anonymisation or pseudonymisation. This means removing or masking information that allows individuals to be identified before the data reaches the AI tool. It's an additional step in the process that requires careful thought and often automation, but it's essential for the company's legal security and ethical operation.
Who Is Responsible for the Data Feeding AI?
Companies that succeed with AI have clearly defined roles in the area of data management. For clarity, we can divide them into: data owners, data stewards, and process owners. In the context of implementing ready-made AI models, these roles are just as important as when a company creates and trains its own model.
An AI model is something users don't fully understand. They often don't know how it works or grasp its mechanisms. And certainly, no user of a publicly available AI model has any influence over how it operates. However, as users, we do have influence over many things. These are primarily: carefully thinking through the process, properly matching the model to the task, and ensuring the quality of input data. If the output of an AI process is poor, the first question should be: "Did we provide the right data?" And to answer that, there must be someone responsible for that data.
We can identify three key roles in data management processes:
Data Owner – the person responsible for a given dataset. They decide what data is collected, who has access to it, and what quality standards apply. In the context of AI: they decide whether data can be used in an AI process and under what conditions.
Data Steward – the person who looks after data quality on a daily basis. They monitor completeness, currency, and consistency. In the context of AI: they ensure the quality of data feeding the process.
Process Owner (AI Process Owner) – the person responsible for the entire business process that utilises AI. They understand what data the process needs and collaborate with data owners to obtain it.
In many organisations, the problem is that nobody formally "owns" the data. IT is responsible for systems (infrastructure), business uses the data, but no one is accountable for its quality. When implementing AI, this can be a significant blocker to progress.
Data Management Is a Board-Level Responsibility, Not IT's
There's a fairly common belief that data management is IT's domain. In the context of AI implementations, this approach can be fatal. The lack of an organisation-wide data acquisition and management strategy makes it difficult to scale AI projects, and as a result, they often fail to progress beyond the pilot stage.
Data management requires C-level engagement in several areas:
- Strategic decisions: Which data is most important for planned AI processes? Which datasets should be invested in first? What data is missing and how can it be obtained? These are decisions about resource allocation and priorities—they cannot be delegated to IT.
- Organisational decisions: Breaking down silos requires intervention at the organisational structure level. A CIO typically doesn't have the formal authority to mandate that the sales department share data with marketing. No AI project leader can force the finance department to provide payment data. These decisions must come from the top.
- Cultural decisions: Building a culture of data accountability is a long-term process. It requires communication, motivation, and enforcement. This is a process that demands management at the organisation-wide level.
- Budget decisions: Getting data in order requires investment. Companies that treat data as a strategic asset and invest in managing it achieve better results with AI. But this investment must be a conscious decision by the board.
This is why one of the key roles to fill in an AI project (the Ownership & Accountability section in the AI Transformation Canvas) is the Executive Sponsor—a person who "removes organizational blockers." Data silos and the lack of data governance are undoubtedly such blockers.
A Practical Framework for Assessing Data Readiness
To make it easier to assess whether your organisation's data is ready for AI, we've prepared a simple framework. You'll find it reflected in the AI Transformation Canvas in the form of questions you should answer before starting a project.
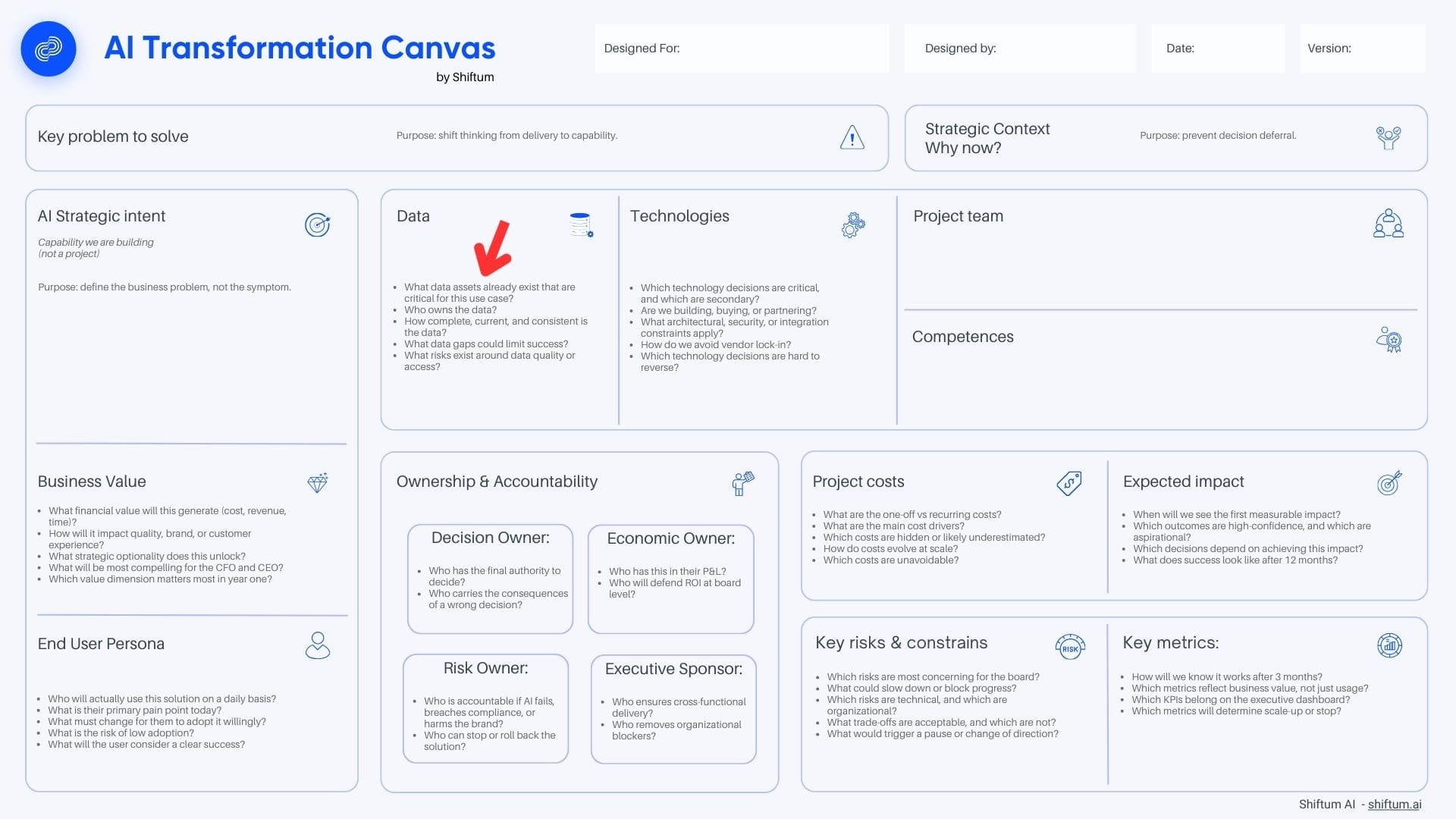
Question 1: What data is critical for this use case?
This is a question about consciously defining requirements. It's not about what data we have—it's about what data the AI process needs to generate value. This requires understanding the logic of how the process works: what information enters the process, what happens to it, and what the end result is. Before you ask "do we have this data?", consider what data you actually need. The list may be shorter than you think—or longer.
Question 2: Who owns this data?
This is a question about accountability. Is there a person responsible for each required dataset? Does this person know their data will be feeding an AI process? Do they agree to share it? If the answer is "probably IT" or "no one specifically," this is a problem that needs solving before the project starts.
Question 3: How complete, current, and consistent is this data?
This is a question about quality. It's not enough for data to exist—it must be usable. Completeness: do we have all the necessary fields for all the necessary records? Currency: when was the data last updated, what's the refresh cycle? Consistency: is data from different sources aligned? Don't rely on declarations—conduct a data quality audit on a sample. Reality often differs significantly from assumptions.
Question 4: What data gaps could limit success?
This is a question about consciously identifying gaps and planning how to address them. Gaps can be absolute (the data doesn't exist and needs to start being collected), relative (the data exists but isn't of sufficient quality), or temporal (the data will be available, but not at project launch). Each identified gap requires a decision—can the project proceed regardless; can gaps be filled in parallel?
Question 5: What risks are associated with data quality or access?
This is a question about risk management. Data can carry legal risks (GDPR, intellectual property), reputational risks (sensitive customer data), operational risks (dependency on an external provider), or quality risks (issues with the data source). Identified risks should be recorded in the "Key risks & constraints" section of the AI Transformation Canvas, with assigned management strategies.
Data as a Prerequisite for AI Success
In the era of ready-made, publicly available AI models, competitive advantage doesn't lie in technology. Everyone has access to the same models. The advantage lies in data—its quality, accessibility, and integration. A company with well-organised data can quickly implement an effective AI process. A company where data is collected and managed chaotically can experiment for years without achieving expected results.
To summarise the key takeaways:
- Data fuels the AI process. The quality of input data that the process relies on directly translates into the quality of results.
- Trust in AI requires trust in data. Without reliable, well-prepared data, even the best AI model won't deliver high-quality output.
- Completeness, currency, consistency, and accessibility—these are the four dimensions of data readiness that must be assessed before every AI project.
- Data silos are an organisational barrier, not a technical one. Breaking them down requires decisions at board level.
- Data anonymisation is a necessity, not a formality. Data sent to external AI tools may be used to train models—without proper anonymisation procedures, you risk GDPR violations and uncontrolled leakage of information about your customers and company.
- Data management is a C-level responsibility. Companies without a data management strategy often stall at the pilot stage due to data not being ready for project needs.
- The five questions from the AI Transformation Canvas in the Data section provide a practical framework for assessing data readiness—use it before every project.
A thorough analysis, which you can conduct with the help of the AI Transformation Canvas, can protect you from costly failure—or give you confidence that your project has truly solid foundations.

Planning to implement an AI project in your organisation?
To help you make the right decisions and properly prepare for this project, we're sharing our proprietary AI Transformation Canvas by Shiftum.
In the canvas, you'll find:
- a ready-to-use framework covering all the key areas of AI project planning
- a blank version, ready to print and work with
- a version with guiding questions for each section, designed to help you understand what information matters at every stage of planning